Web-Development-Interview
🍃 MongoDB Interview Guide
Table of Contents
- Introduction to MongoDB
- Basic Concepts
- CRUD Operations
- Indexing
- Sharding
- Replication
- Schema Design
- Data Types
- Aggregation
- Transactions
- Advanced Queries
- Performance Optimization
- Security
- Best Practices
Introduction to MongoDB
Q1: What is MongoDB and how does it differ from traditional relational databases?
🎓 Expert Explanation: MongoDB is a popular NoSQL database that stores data in flexible, JSON-like documents called BSON (Binary JSON). Unlike traditional relational databases that use tables and rows, MongoDB uses collections and documents.
🔍 Key Differences:
-
Schema Flexibility: MongoDB allows for dynamic schemas, meaning each document in a collection can have a different structure. This is particularly useful for evolving data models.
-
Scalability: MongoDB is designed to scale horizontally, making it easier to distribute data across multiple servers.
-
Query Language: Instead of SQL, MongoDB uses a rich query language based on JavaScript.
-
Data Model: MongoDB’s document model allows for embedding related data within a single document, reducing the need for joins.
🏗️ Use Case: Imagine you’re building a social media platform. User profiles in MongoDB might look like this:
{
"_id": ObjectId("5f8a7b2b9d3b2c1a3c5d7e9f"),
"username": "tech_guru",
"email": "guru@techworld.com",
"interests": ["AI", "Machine Learning", "Cloud Computing"],
"posts": [
{
"title": "The Future of AI",
"content": "AI is revolutionizing...",
"comments": [
{"user": "ai_fan", "text": "Great insights!"},
{"user": "skeptic101", "text": "But what about..."}
]
}
]
}
In a relational database, this data would be split across multiple tables (Users, Posts, Comments), requiring joins for retrieval. MongoDB allows us to store this hierarchical data in a single document, making reads faster and more intuitive.
🎨 Novice Explanation: Think of MongoDB as a giant digital notebook 📓. Each page in this notebook is a document that can contain any information you want - text, numbers, lists, even smaller notebooks (embedded documents)! You don’t need to decide the structure of your pages beforehand; you can add or remove sections as you go. This flexibility is like having a magical notebook that adapts to your needs, unlike traditional databases which are more like rigid forms where you have to fill in predefined boxes.

Basic Concepts
Q2: Explain the difference between a collection and a document in MongoDB.
🎓 Expert Explanation: In MongoDB, collections and documents are fundamental concepts that form the core of its data model.
- Document:
- A document is the basic unit of data in MongoDB.
- It’s analogous to a row in relational databases but more flexible.
- Documents are stored in BSON (Binary JSON) format.
- Each document can have a different structure within the same collection.
- Collection:
- A collection is a grouping of MongoDB documents.
- It’s analogous to a table in relational databases.
- Collections do not enforce a schema, allowing for document flexibility.
🔍 Key Differences:
| Aspect | Document | Collection |
|---|---|---|
| Definition | Individual record | Group of documents |
| Structure | Flexible, can vary between documents | No fixed structure |
| Analogy | Row in a relational DB | Table in a relational DB |
| Contents | Fields and values | Multiple documents |
🏗️ Use Case: Let’s consider an e-commerce application:
// 'products' collection
{
"_id": ObjectId("5f8a7b2b9d3b2c1a3c5d7e9f"),
"name": "Smartphone X",
"price": 999.99,
"category": "Electronics",
"specs": {
"screen": "6.5 inch",
"battery": "4000mAh"
}
}
{
"_id": ObjectId("5f8a7c3c9d3b2c1a3c5d7ea0"),
"name": "Cotton T-Shirt",
"price": 19.99,
"category": "Apparel",
"sizes": ["S", "M", "L", "XL"]
}
Here, products is a collection, and each item within it is a document. Notice how the documents can have different fields (specs for the smartphone, sizes for the t-shirt) within the same collection.
🎨 Novice Explanation: Imagine a big filing cabinet 🗄️. This cabinet is your MongoDB database. Inside this cabinet, you have several folders 📁 - these are your collections. Each collection (folder) contains many papers 📄 - these are your documents. Just like how you can put different types of papers in a folder, you can put different types of information in a MongoDB collection!
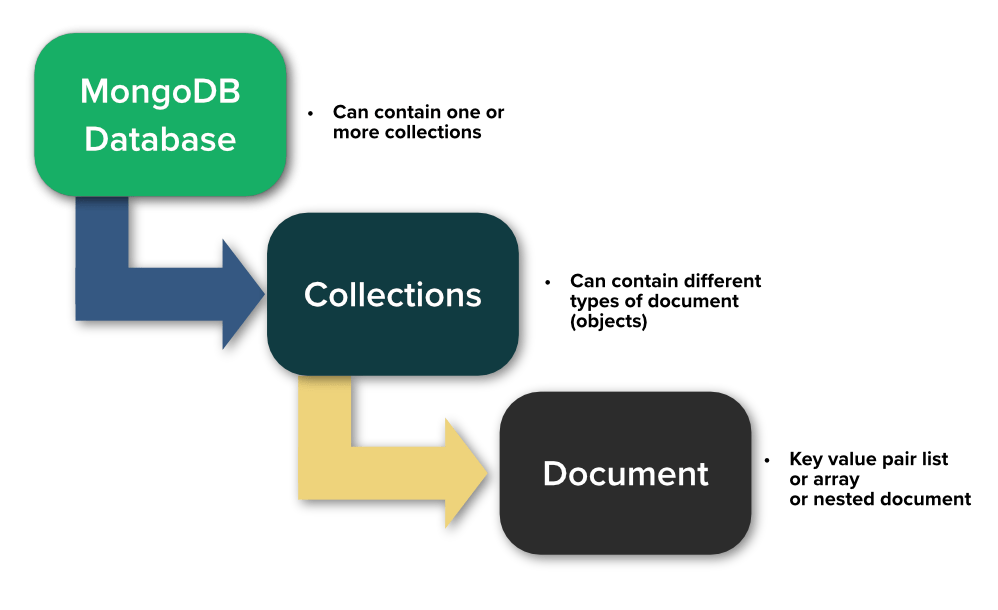
Q3: What are the advantages of using MongoDB?
🎓 Expert Explanation: MongoDB offers several advantages that make it a popular choice for modern application development:
- Flexible Schema:
- Allows for dynamic, evolving data models.
- Particularly useful in agile development environments.
- Scalability:
- Supports horizontal scaling through sharding.
- Can handle large volumes of data and high traffic loads.
- Performance:
- Offers high read/write throughput for big data applications.
- Supports in-memory storage engine for faster data access.
- Rich Query Language:
- Supports complex queries, full-text search, and aggregation.
- Allows for geospatial queries.
- High Availability:
- Supports replica sets for automated failover and data redundancy.
- Document-Oriented:
- Allows for easier mapping of objects in application code.
- Reduces need for complex joins.
- Support for Multiple Storage Engines:
- WiredTiger and in-memory storage engines available.
- Aggregation Framework:
- Powerful tool for data analysis and reporting.
- Native Drivers:
- Official drivers available for many programming languages.
- Large and Active Community:
- Extensive documentation and community support.
🏗️ Use Case: Consider a real-time analytics platform for a social media application:
// User interaction document
{
"_id": ObjectId("5f8a7d4d9d3b2c1a3c5d7ea1"),
"user_id": "user123",
"event": "post_like",
"post_id": "post456",
"timestamp": ISODate("2023-07-23T10:30:00Z"),
"location": {
"type": "Point",
"coordinates": [-73.935242, 40.730610]
},
"device": "mobile_ios"
}
MongoDB’s advantages shine here:
- The flexible schema allows for easy addition of new fields (e.g.,
device). - Geospatial indexing supports location-based queries.
- Sharding enables handling millions of such interactions per second.
- The aggregation framework can provide real-time insights on user behavior.
🎨 Novice Explanation: Think of MongoDB as a super-flexible, turbocharged notebook system 📓💨. It’s like having a magical notebook that can grow as big as you need (scalability), understand and find information in many ways (rich queries), and even split itself into many notebooks that work together (sharding). Plus, it’s really good at understanding all sorts of information, from text to locations on a map! 🗺️
CRUD Operations
Q4: How do you perform CRUD operations in MongoDB?
🎓 Expert Explanation: CRUD operations in MongoDB refer to Create, Read, Update, and Delete operations on documents. Let’s explore each operation with examples:
-
Create (Insert)
MongoDB provides two methods for inserting documents:
insertOne(): Inserts a single documentinsertMany(): Inserts multiple documents
Example:
db.users.insertOne({ name: "John Doe", email: "john@example.com", age: 30 }) db.users.insertMany([ { name: "Jane Smith", email: "jane@example.com", age: 28 }, { name: "Bob Johnson", email: "bob@example.com", age: 35 } ]) -
Read (Query)
MongoDB offers several methods for querying documents:
find(): Retrieves multiple documentsfindOne(): Retrieves a single document
Example:
// Find all users db.users.find() // Find users aged 30 db.users.find({ age: 30 }) // Find one user named John Doe db.users.findOne({ name: "John Doe" }) -
Update
MongoDB provides methods for updating documents:
updateOne(): Updates a single documentupdateMany(): Updates multiple documentsreplaceOne(): Replaces a document
Example:
// Update John Doe's age db.users.updateOne( { name: "John Doe" }, { $set: { age: 31 } } ) // Increment age of all users by 1 db.users.updateMany( {}, { $inc: { age: 1 } } ) -
Delete
MongoDB offers methods for deleting documents:
deleteOne(): Deletes a single documentdeleteMany(): Deletes multiple documents
Example:
// Delete user John Doe db.users.deleteOne({ name: "John Doe" }) // Delete all users aged over 50 db.users.deleteMany({ age: { $gt: 50 } })
🏗️ Use Case: Let’s consider a blog application:
// Create a new post
db.posts.insertOne({
title: "Introduction to MongoDB",
content: "MongoDB is a powerful NoSQL database...",
author: "tech_guru",
tags: ["database", "NoSQL"],
createdAt: new Date()
})
// Read all posts by tech_guru
db.posts.find({ author: "tech_guru" })
// Update post title
db.posts.updateOne(
{ title: "Introduction to MongoDB" },
{ $set: { title: "MongoDB: A Comprehensive Guide" } }
)
// Delete posts older than a year
const oneYearAgo = new Date(new Date().setFullYear(new Date().getFullYear() - 1))
db.posts.deleteMany({ createdAt: { $lt: oneYearAgo } })
🎨 Novice Explanation: Imagine you have a magical notebook 📓✨:
- Create is like writing a new page in your notebook 📝
- Read is like flipping through pages to find information 🔍
- Update is like erasing and rewriting parts of a page ✏️
- Delete is like tearing out a page you don’t need anymore 🗑️
MongoDB gives you special commands to do all these actions quickly and easily, even if your notebook has millions of pages!
Indexing
Q5: What is the purpose of the _id field in MongoDB?
🎓 Expert Explanation:
The _id field in MongoDB serves as a unique identifier for each document within a collection. It’s a special field with several important characteristics:
-
Uniqueness: The
_idfield is always unique within a collection, ensuring that each document can be distinctly identified. -
Primary Key: It acts as the primary key for the document, similar to primary keys in relational databases.
-
Automatic Generation: If not provided by the user during insertion, MongoDB automatically generates an
_idfield. - Default Type: By default, the
_idfield is an ObjectId, a 12-byte BSON type that consists of:- 4-byte timestamp value, representing the ObjectId’s creation, measured in seconds since the Unix epoch
- 5-byte random value
- 3-byte incrementing counter, initialized to a random value
-
Indexing: MongoDB automatically creates an index on the
_idfield, which aids in quick retrieval of documents. - Immutability: Once set, the
_idfield’s value cannot be changed.
🏗️ Use Case: Consider a user management system:
// Inserting a document without specifying _id
db.users.insertOne({
name: "Alice Smith",
email: "alice@example.com"
})
// MongoDB generates an _id automatically
// The inserted document might look like:
{
"_id" : ObjectId("60d5ec9f0a86b111a8261f57"),
"name" : "Alice Smith",
"email" : "alice@example.com"
}
// Inserting a document with a custom _id
db.users.insertOne({
"_id": "user_bob",
"name": "Bob Johnson",
"email": "bob@example.com"
})
// The inserted document will use the provided _id
{
"_id" : "user_bob",
"name" : "Bob Johnson",
"email" : "bob@example.com"
}
🎨 Novice Explanation:
Imagine you’re organizing a huge library 📚. Every book needs a unique code so you can find it easily. In MongoDB, the _id is like this unique code for each piece of information (document). If you don’t give a book a code, the library (MongoDB) automatically puts a special sticker (ObjectId) on it. This way, no matter how many books you have, each one can be quickly and easily found! 🔍📕
Q6: How do you create an index in MongoDB and why are indexes important?
🎓 Expert Explanation: Indexes in MongoDB are special data structures that store a small portion of the collection’s data set in an easy-to-traverse form. They significantly improve the speed of read operations but can slow down write operations.
Creating an Index:
To create an index, you use the createIndex() method. The basic syntax is:
db.collection.createIndex( <key and index type specification>, <options> )
Types of Indexes:
- Single Field Index
- Compound Index
- Multikey Index (for arrays)
- Text Index
- Geospatial Index
- Hashed Index
Importance of Indexes:
- Query Performance: Indexes can dramatically speed up query execution.
- Sort Operations: Indexes can support efficient sorting.
- Unique Constraints: Can enforce uniqueness of field values.
- Covered Queries: Queries can be satisfied entirely using the index.
🏗️ Use Case: Let’s consider a large collection of books in an online bookstore:
// Create a single field index on 'title'
db.books.createIndex({ title: 1 })
// Create a compound index on 'author' and 'publishedDate'
db.books.createIndex({ author: 1, publishedDate: -1 })
// Create a text index for full-text search
db.books.createIndex({ description: "text" })
// Create a geospatial index for location-based queries
db.bookstores.createIndex({ location: "2dsphere" })
// Query examples
db.books.find({ title: "MongoDB Basics" }) // Uses title index
db.books.find({ author: "John Doe" }).sort({ publishedDate: -1 }) // Uses compound index
db.books.find({ $text: { $search: "database" } }) // Uses text index
db.bookstores.find({ location: { $near: { $geometry: { type: "Point", coordinates: [ -73.9667, 40.78 ] } } } }) // Uses geospatial index
🎨 Novice Explanation: Think of a book with an index at the back 📚. Without it, you’d have to flip through every page to find what you want. The index lets you jump right to the information you need. MongoDB indexes work the same way! They’re like super-powered bookmarks 🔖 that help MongoDB find your data super fast, without having to look at every single piece of information.
Sharding
Q7: Explain the concept of sharding in MongoDB.
🎓 Expert Explanation: Sharding is MongoDB’s approach to horizontal scaling. It involves distributing data across multiple machines to support deployments with very large data sets and high throughput operations.
Key Concepts:
- Shard: A shard is a subset of the data. Each shard is deployed as a replica set.
- Shard Key: The shard key determines how the data in a collection is distributed across the shards.
- Config Servers: These store metadata and configuration settings for the cluster.
- Mongos: This is the query router that directs operations to the appropriate shard(s).
Sharding Process:
- Choose a shard key
- Split data into chunks based on the shard key
- Distribute chunks across shards
Benefits of Sharding:
- Horizontal Scalability
- Increased Read/Write Throughput
- Increased Storage Capacity
- Data Locality
🏗️ Use Case: Imagine an e-commerce platform that needs to handle millions of products and transactions:
// Enable sharding for a database
sh.enableSharding("ecommerce")
// Shard the products collection using the category and price as the shard key
sh.shardCollection("ecommerce.products", { category: 1, price: 1 })
// Insert a product (MongoDB will automatically route it to the appropriate shard)
db.products.insertOne({
name: "Smartphone X",
category: "electronics",
price: 999.99,
stock: 500
})
// Query for products (MongoDB will query the appropriate shard(s))
db.products.find({ category: "electronics", price: { $gt: 500 } })
In this scenario, sharding allows the e-commerce platform to:
- Scale horizontally as the product catalog grows
- Distribute read/write operations across multiple servers
- Maintain performance even with millions of products and concurrent users
🎨 Novice Explanation: Imagine you have a huge box of LEGO bricks 🧱, and you want to sort them. Instead of one person sorting all the bricks, you ask your friends to help. You give each friend (shard) a specific type of brick to sort (shard key). Now, when you need a particular brick, you know exactly which friend to ask! This is how MongoDB uses sharding to handle enormous amounts of data efficiently.

Replication
Q8: What is replication in MongoDB and how does it work?
🎓 Expert Explanation: Replication in MongoDB is the practice of maintaining multiple copies of your data on different database servers. This provides redundancy and increases data availability.
Key Concepts:
- Replica Set: A group of mongod instances that maintain the same data set.
- Primary Node: The primary member receives all write operations.
- Secondary Nodes: These members replicate the primary’s data set.
- Oplog (Operations Log): A special capped collection that keeps a rolling record of all operations that modify the data stored in your databases.
How Replication Works:
- All write operations go to the primary.
- The primary records all changes in its oplog.
- Secondary nodes replicate the primary’s oplog and apply the operations to their data sets.
- If the primary becomes unavailable, an election process chooses a new primary from the available secondaries.
Benefits of Replication:
- High Availability
- Disaster Recovery
- Read Scaling
- Data Redundancy
🏗️ Use Case: Consider a financial application that requires high availability:
// Replica Set Configuration (in mongo shell)
rs.initiate({
_id: "financeRS",
members: [
{ _id: 0, host: "mongodb0.example.net:27017" },
{ _id: 1, host: "mongodb1.example.net:27017" },
{ _id: 2, host: "mongodb2.example.net:27017" }
]
})
// Writing to the primary
db.transactions.insertOne({
user: "Alice",
amount: 1000,
type: "deposit",
date: new Date()
})
// Reading from a secondary (need to set read preference)
db.transactions.find().readPref("secondary")
In this scenario:
- The application writes all transactions to the primary.
- If the primary goes down, one of the secondaries is automatically elected as the new primary.
- The application can distribute read operations among secondaries for better performance.
🎨 Novice Explanation: Think of replication like having backup singers in a band 🎤👥. The lead singer (primary node) sings the main part, and the backup singers (secondary nodes) learn and sing the same song. If the lead singer loses their voice, one of the backup singers can step up and become the new lead. This way, the show (your data) always goes on!

Schema Design
Q9: How do you handle schema design in MongoDB?
🎓 Expert Explanation: Schema design in MongoDB is flexible and allows for evolving data models. Unlike traditional relational databases, MongoDB doesn’t enforce a strict schema. However, thoughtful schema design is crucial for optimal performance and scalability.
Key Principles:
- Embed vs. Reference: Decide whether to embed related data or use references.
- Data Access Patterns: Design your schema based on how the application will access and manipulate data.
- Document Growth: Consider how documents might grow over time.
- Indexing Strategy: Plan your indexes along with your schema.
- Data Life Cycle: Consider how data will be created, read, updated, and deleted.
Schema Design Patterns:
- Embedded Documents: For one-to-one or one-to-few relationships.
- References: For one-to-many or many-to-many relationships.
- Bucket Pattern: For time-series or IoT data.
- Extended Reference Pattern: Denormalize frequently accessed data.
- Subset Pattern: Store a subset of data from a large document.
🏗️ Use Case: Let’s design a schema for a blogging platform:
// Blog Post Document
{
_id: ObjectId("5f8a7b2b9d3b2c1a3c5d7e9f"),
title: "Introduction to MongoDB Schema Design",
content: "MongoDB's flexible schema allows...",
author: {
_id: ObjectId("5f8a7b2b9d3b2c1a3c5d7e8e"),
name: "John Doe",
email: "john@example.com"
},
tags: ["MongoDB", "Database", "NoSQL"],
comments: [
{
user: "Alice",
text: "Great article!",
date: ISODate("2023-07-23T10:00:00Z")
},
{
user: "Bob",
text: "Thanks for the explanation.",
date: ISODate("2023-07-23T11:30:00Z")
}
],
created_at: ISODate("2023-07-22T09:00:00Z"),
updated_at: ISODate("2023-07-23T12:00:00Z")
}
// User Document (referenced by blog post)
{
_id: ObjectId("5f8a7b2b9d3b2c1a3c5d7e8e"),
name: "John Doe",
email: "john@example.com",
bio: "Passionate about technology and writing.",
posts: [ObjectId("5f8a7b2b9d3b2c1a3c5d7e9f"), ...]
}
In this design:
- We embed the author’s basic info in the blog post for quick access.
- Comments are embedded as they’re always accessed with the post.
- Tags are stored as an array for easy querying.
- The user document contains a reference to their posts.
🎨 Novice Explanation: Designing a MongoDB schema is like organizing a big toolbox 🧰. You want to put the tools you often use together in easy-to-reach compartments (embedding), while keeping some specialized tools in separate drawers but with labels pointing to them (referencing). The goal is to arrange everything so you can find and use your tools (data) quickly and easily when you need them!
Data Types
Q10: What are the different data types supported by MongoDB?
🎓 Expert Explanation: MongoDB supports a rich set of data types, allowing for flexible and expressive data modeling. Here are the main data types:
- String: UTF-8 encoded string.
- Integer: 32-bit or 64-bit integer.
- Double: 64-bit IEEE 754 floating point number.
- Boolean: true or false.
- Date: Stored as 64-bit integer representing milliseconds since the Unix epoch.
- Null: Represents a null value or field that doesn’t exist.
- ObjectId: 12-byte identifier, typically used for
_idfields. - Array: List or multiple values stored in a single field.
- Embedded Document: Complete documents embedded as values in a field.
- Binary Data: For storing binary data.
- Regular Expression: For storing regular expression patterns.
- JavaScript: For storing JavaScript code.
- Timestamp: Internal MongoDB type for tracking when documents were modified.
- Decimal128: 128-bit decimal-based floating-point value for high precision calculations.
🏗️ Use Case: Let’s consider a product catalog for an e-commerce platform:
db.products.insertOne({
_id: ObjectId("5f8a7b2b9d3b2c1a3c5d7e9f"),
name: "Smartphone X",
price: NumberDecimal("999.99"),
inStock: true,
categories: ["electronics", "mobile"],
specs: {
screen: "6.5 inch",
battery: "4000mAh",
camera: "48MP"
},
releaseDate: new Date("2023-07-15"),
tags: /^smart.*/i,
lastModified: new Timestamp(),
description: "A cutting-edge smartphone with...",
thumbnail: BinData(0, "base64EncodedImageData..."),
ratings: [4.5, 5, 4.8, 4.2]
})
This document showcases various data types:
_id: ObjectIdname: Stringprice: Decimal128 (for precise currency values)inStock: Booleancategories: Array of Stringsspecs: Embedded DocumentreleaseDate: Datetags: Regular ExpressionlastModified: Timestampdescription: Stringthumbnail: Binary Dataratings: Array of Doubles
🎨 Novice Explanation: Imagine you have a magical box 📦✨ that can hold all sorts of things - numbers, words, lists, even smaller boxes! MongoDB is like this magical box. It can store many different types of information, from simple things like numbers and words, to complex things like dates, special codes, and even entire collections of other information. This flexibility allows you to organize your data in ways that make the most sense for your specific needs!
Aggregation
Q11: How do you perform aggregation operations in MongoDB?
🎓 Expert Explanation: Aggregation in MongoDB is a way of processing a large number of documents in a collection by means of passing them through different stages. The aggregation pipeline consists of one or more stages that process documents:
- Each stage performs an operation on the input documents.
- The documents that are output from a stage are passed to the next stage.
- The final stage outputs the results of the aggregation.
Key Aggregation Stages:
$match: Filters the documents.$group: Groups documents by a specified expression.$sort: Sorts the documents.$project: Reshapes documents (add/remove fields, create computed fields).$limitand$skip: Control the number of documents in the output.$unwind: Deconstructs an array field from the input documents.$lookup: Performs a left outer join to another collection.
🏗️ Use Case: Let’s consider a sales database for a company with multiple products and locations:
db.sales.aggregate([
// Stage 1: Match sales from the year 2023
{
$match: {
date: {
$gte: new Date("2023-01-01"),
$lt: new Date("2024-01-01")
}
}
},
// Stage 2: Group by product and calculate total sales
{
$group: {
_id: "$product",
totalQuantity: { $sum: "$quantity" },
totalRevenue: { $sum: { $multiply: ["$price", "$quantity"] } }
}
},
// Stage 3: Sort by total revenue in descending order
{
$sort: { totalRevenue: -1 }
},
// Stage 4: Limit to top 5 products
{
$limit: 5
},
// Stage 5: Project the final output format
{
$project: {
product: "$_id",
totalQuantity: 1,
totalRevenue: { $round: ["$totalRevenue", 2] },
averagePrice: {
$round: [{ $divide: ["$totalRevenue", "$totalQuantity"] }, 2]
}
}
}
])
This aggregation pipeline:
- Filters sales for the year 2023
- Groups the sales by product and calculates total quantity and revenue
- Sorts products by total revenue
- Limits the output to the top 5 products
- Reshapes the output to include the average price
🎨 Novice Explanation: Think of MongoDB aggregation like a fancy coffee machine ☕️. You put in your raw coffee beans (your data), and then you can set up different steps: grinding the beans ($match), sorting them ($sort), mixing with water ($group), and finally, pouring into cups ($project). Each step prepares your data in a specific way, and at the end, you get exactly the “coffee” (information) you wanted!
Transactions
Q12: How do you perform transactions in MongoDB and what are their limitations?
🎓 Expert Explanation: MongoDB supports multi-document ACID transactions starting from version 4.0 for replica sets and 4.2 for sharded clusters. Transactions allow you to execute multiple operations in isolation and potentially roll them back if any part of the transaction fails.
Key Concepts:
- Start Transaction: Begin a new transaction.
- Execute Operations: Perform read and write operations within the transaction.
- Commit Transaction: Save all changes made during the transaction.
- Abort Transaction: Roll back all changes if an error occurs.
Syntax:
const session = client.startSession();
session.startTransaction();
try {
// Perform operations
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
} finally {
session.endSession();
}
Limitations:
- Performance Overhead: Transactions can impact performance, especially for write-heavy workloads.
- Lock Conflicts: Long-running transactions may cause lock conflicts.
- Size Limits: Transactions have a 16MB size limit.
- Time Limits: Default transaction timeout is 60 seconds.
- Sharded Clusters: Cross-shard transactions have additional complexity and performance considerations.
🏗️ Use Case: Let’s consider a banking application where we need to transfer money between two accounts:
const session = client.startSession();
session.startTransaction();
try {
const accounts = client.db("bank").collection("accounts");
// Deduct amount from sender's account
await accounts.updateOne(
{ accountId: "sender123" },
{ $inc: { balance: -100 } },
{ session }
);
// Add amount to receiver's account
await accounts.updateOne(
{ accountId: "receiver456" },
{ $inc: { balance: 100 } },
{ session }
);
await session.commitTransaction();
console.log("Transaction successful");
} catch (error) {
await session.abortTransaction();
console.log("Transaction failed:", error);
} finally {
await session.endSession();
}
In this scenario, the transaction ensures that either both accounts are updated or neither is, maintaining the integrity of the transfer operation.
🎨 Novice Explanation: Imagine you’re moving furniture between two rooms 🏠. You want to make sure that if you take a chair from one room, it definitely ends up in the other room - not stuck in the hallway! MongoDB transactions are like having a magic spell ✨ that ensures everything moves correctly, or if something goes wrong, everything goes back to how it was before you started. It’s a way to keep your data safe and consistent, especially when you’re making multiple changes at once.
Advanced Queries
Q13: How do you use the $lookup operator for joins in MongoDB?
🎓 Expert Explanation:
The $lookup operator in MongoDB performs a left outer join to another collection in the same database. It’s part of the aggregation pipeline and allows you to combine documents from two collections based on a specified condition.
Basic Syntax:
{
$lookup: {
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
Advanced Syntax (MongoDB 5.0+):
{
$lookup: {
from: <collection to join>,
let: { <var_1>: <expression>, …, <var_n>: <expression> },
pipeline: [ <pipeline to execute on the joined collection> ],
as: <output array field>
}
}
🏗️ Use Case: Let’s consider an e-commerce platform with separate collections for orders and products:
db.orders.aggregate([
{
$lookup: {
from: "products",
localField: "items.productId",
foreignField: "_id",
as: "productDetails"
}
},
{
$project: {
orderId: 1,
date: 1,
items: {
$map: {
input: "$items",
as: "item",
in: {
productId: "$$item.productId",
quantity: "$$item.quantity",
details: {
$arrayElemAt: [
{
$filter: {
input: "$productDetails",
cond: { $eq: ["$$this._id", "$$item.productId"] }
}
},
0
]
}
}
}
}
}
}
])
This aggregation:
- Uses
$lookupto join theordersandproductscollections. - Uses
$projectwith$mapand$filterto reshape the output, matching each ordered item with its product details.
🎨 Novice Explanation:
Imagine you’re planning a big party 🎉 and you have two lists: one with guest names and their favorite color, and another with color themes and decorations. The $lookup operator is like a party planner that matches each guest with the right decorations based on their favorite color. It brings information together from different lists to create a complete party plan!
Q14: Explain the difference between findOne() and find() methods in MongoDB.
🎓 Expert Explanation:
Both findOne() and find() are methods used to query documents in MongoDB, but they have some key differences:
- Return Value:
findOne(): Returns a single document that satisfies the query criteria.find(): Returns a cursor to the documents that match the query criteria.
- Number of Results:
findOne(): Returns at most one document, even if multiple documents match the query.find(): Can return multiple documents (all that match the query).
- Performance:
findOne(): Generally faster for retrieving a single document as it stops searching after finding the first match.find(): Searches through all documents that match the criteria.
- Usage:
findOne(): Typically used when you expect or need only one result (e.g., looking up by a unique identifier).find(): Used when you want to retrieve multiple documents or perform further operations on the result set.
- Cursor Operations:
findOne(): Returns the document directly, no cursor operations are available.find(): Returns a cursor, allowing for additional operations like sorting, limiting, or skipping results.
🏗️ Use Case: Let’s consider a user management system:
// Using findOne() to retrieve a specific user by username
const user = await db.users.findOne({ username: "johndoe" });
console.log(user);
// Using find() to retrieve all active users
const activeCursor = db.users.find({ status: "active" });
const activeUsers = await activeCursor.toArray();
console.log(activeUsers);
// Using find() with additional cursor operations
const recentUsersCursor = db.users.find({ status: "active" })
.sort({ lastLogin: -1 })
.limit(10);
const recentUsers = await recentUsersCursor.toArray();
console.log(recentUsers);
In these examples:
findOne()is used to fetch a single user by their unique username.find()is used to fetch all active users, and in the second case, to fetch the 10 most recently active users with sorting and limiting.
🎨 Novice Explanation:
Think of findOne() and find() like fishing 🎣:
findOne()is like catching the first fish you find. You cast your line, catch a fish, and you’re done!find()is like casting a net. You might catch many fish, and then you can choose which ones you want to keep or how to sort them.
Both help you get fish (data), but in different ways depending on what you need!
Performance Optimization
Q15: What strategies can you use to optimize MongoDB performance?
🎓 Expert Explanation: Optimizing MongoDB performance involves various strategies across different aspects of database design and usage:
- Indexing:
- Create appropriate indexes based on your query patterns.
- Use compound indexes for queries with multiple fields.
- Avoid over-indexing, as it can slow down write operations.
- Query Optimization:
- Use query analyzers like
explain()to understand query performance. - Optimize queries to use existing indexes.
- Avoid querying for unnecessary fields.
- Use query analyzers like
- Schema Design:
- Design schemas that match your application’s data access patterns.
- Consider embedding vs. referencing based on data relationships and access patterns.
- Data Models:
- Use appropriate data types to save space and improve query performance.
- Consider using the Bucket Pattern for time-series data.
- Aggregation Pipeline:
- Place
$matchand$limitstages early in the pipeline to reduce the amount of data processed. - Use
$projectto include only necessary fields.
- Place
- Hardware and Infrastructure:
- Use SSDs for better I/O performance.
- Ensure adequate RAM for your working set.
- Consider sharding for horizontal scaling.
- Connection Pooling:
- Use connection pools to reduce the overhead of creating new connections.
- Monitoring and Profiling:
- Use MongoDB’s built-in monitoring tools to identify slow queries and performance bottlenecks.
🏗️ Use Case: Let’s optimize a social media application’s post retrieval system:
// Before optimization
db.posts.find({ author: "user123", date: { $gte: ISODate("2023-01-01") } })
.sort({ likes: -1 })
.limit(10)
// After optimization
// 1. Create a compound index
db.posts.createIndex({ author: 1, date: -1, likes: -1 })
// 2. Optimize the query
db.posts.find({
author: "user123",
date: { $gte: ISODate("2023-01-01") }
})
.hint({ author: 1, date: -1, likes: -1 })
.limit(10)
// 3. Use projection to fetch only necessary fields
db.posts.find({
author: "user123",
date: { $gte: ISODate("2023-01-01") }
}, { title: 1, content: 1, likes: 1 })
.hint({ author: 1, date: -1, likes: -1 })
.limit(10)
// 4. Analyze the query performance
db.posts.find({
author: "user123",
date: { $gte: ISODate("2023-01-01") }
}, { title: 1, content: 1, likes: 1 })
.hint({ author: 1, date: -1, likes: -1 })
.limit(10)
.explain("executionStats")
These optimizations:
- Create a compound index to support the query.
- Use
hint()to ensure the query uses the correct index. - Use projection to fetch only necessary fields, reducing data transfer.
- Use
explain()to analyze query performance.
🎨 Novice Explanation: Optimizing MongoDB is like tuning a race car 🏎️. You want to make sure every part is working efficiently:
- Indexes are like a GPS system, helping you find information quickly.
- Good schema design is like having a streamlined body shape, reducing resistance.
- Query optimization is like fine-tuning the engine, making sure it runs smoothly.
- And monitoring is like having sensors all over the car, telling you exactly how it’s performing.
The goal is to make your database run as fast and efficiently as possible, just like you want your race car to zoom around the track! 🏁
Security
Q16: What are some key security features and best practices in MongoDB?
🎓 Expert Explanation: Securing MongoDB involves multiple layers of protection:
- Authentication:
- Enable authentication and use strong passwords.
- Use MongoDB’s role-based access control (RBAC) to manage user permissions.
- Encryption:
- Use TLS/SSL for encrypted connections.
- Implement encryption at rest to protect data on disk.
- Network Security:
- Use firewalls to restrict access to MongoDB ports.
- Bind MongoDB to specific IP addresses.
- Audit Logging:
- Enable audit logging to track access and changes to the database.
- Regular Updates:
- Keep MongoDB and drivers up to date with the latest security patches.
- Principle of Least Privilege:
- Grant users only the permissions they need to perform their tasks.
- Secure Configuration:
- Disable or restrict direct server access.
- Use security checklists provided by MongoDB.
- Data Validation:
- Use schema validation to ensure data integrity.
- Backup and Recovery:
- Regularly backup your data and test recovery procedures.
🏗️ Use Case: Let’s implement some security measures for a MongoDB deployment:
// 1. Enable authentication
use admin
db.createUser({
user: "adminUser",
pwd: "securePassword123",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
})
// 2. Create application-specific user with restricted permissions
use myApp
db.createUser({
user: "appUser",
pwd: "appPassword456",
roles: [ { role: "readWrite", db: "myApp" } ]
})
// 3. Enable authorization in mongod.conf
// security:
// authorization: enabled
// 4. Connect with authentication
mongo --port 27017 -u "appUser" -p "appPassword456" --authenticationDatabase "myApp"
// 5. Use TLS/SSL (in mongod.conf)
// net:
// ssl:
// mode: requireSSL
// PEMKeyFile: /path/to/mongodb.pem
// 6. Enable audit logging (in mongod.conf)
// auditLog:
// destination: file
// format: JSON
// path: /var/log/mongodb/audit.json
// 7. Implement schema validation
db.createCollection("users", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["username", "email"],
properties: {
username: {
bsonType: "string",
description: "must be a string and is required"
},
email: {
bsonType: "string",
pattern: "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$",
description: "must be a valid email address and is required"
}
}
}
}
})
These measures implement authentication, authorization, encryption, audit logging, and data validation to enhance the security of the MongoDB deployment.
🎨 Novice Explanation: Securing MongoDB is like protecting a treasure chest 🏴☠️💰:
- Authentication is like having a special key 🔑 to open the chest.
- Encryption is like putting the treasure in a secret code 🔐.
- Network security is like surrounding your treasure with guards 💂.
- Audit logging is like keeping a record of everyone who looks at the treasure 📜.
- And regular updates are like constantly improving your defenses 🛡️.
All these work together to keep your precious data safe from pirates (hackers)! ⚔️
Best Practices
Q17: What are some MongoDB best practices for scalability and maintainability?
🎓 Expert Explanation: Adhering to best practices ensures that your MongoDB deployment remains scalable, maintainable, and performant:
- Design with Scalability in Mind:
- Plan for horizontal scaling (sharding) from the beginning.
- Choose appropriate shard keys based on your data distribution and access patterns.
- Optimize Schema Design:
- Design schemas that support your application’s query patterns.
- Use embedding for “contains” relationships and referencing for “many-to-many” relationships.
- Indexing Strategy:
- Create indexes to support your common queries, but be mindful of the impact on write performance.
- Use compound indexes for queries that filter on multiple fields.
- Write Concern and Read Preference:
- Choose appropriate write concern levels based on your durability requirements.
- Use read preferences to distribute read operations across secondary nodes in a replica set.
- Data Lifecycle Management:
- Implement a data archiving strategy for old or infrequently accessed data.
- Use time-to-live (TTL) indexes for data that should expire automatically.
- Monitoring and Alerting:
- Set up comprehensive monitoring for your MongoDB deployment.
- Configure alerts for critical metrics like disk space, connection count, and replication lag.
- Regular Backups:
- Implement a robust backup strategy and regularly test your restore procedures.
- Use Latest Stable Versions:
- Keep your MongoDB instances updated to benefit from performance improvements and bug fixes.
- Connection Pooling:
- Use connection pooling in your application to efficiently manage database connections.
- Avoid Unbounded Arrays:
- Be cautious with arrays that can grow indefinitely, as they can impact performance.
🏗️ Use Case: Let’s implement some of these best practices in a social media application:
// 1. Schema Design: User document with embedded posts
db.users.insertOne({
username: "johndoe",
email: "john@example.com",
profile: {
name: "John Doe",
age: 30,
location: "New York"
},
recentPosts: [
{ title: "My first post", content: "Hello, MongoDB!", likes: 10 },
{ title: "Learning best practices", content: "MongoDB is awesome!", likes: 15 }
]
})
// 2. Indexing Strategy
db.users.createIndex({ username: 1 }, { unique: true })
db.users.createIndex({ "profile.location": 1, "recentPosts.likes": -1 })
// 3. Time-to-Live Index for session data
db.sessions.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 })
// 4. Write Concern for critical operations
db.users.updateOne(
{ username: "johndoe" },
{ $set: { "profile.verified": true } },
{ writeConcern: { w: "majority", wtimeout: 5000 } }
)
// 5. Read Preference for distributing read load
db.users.find().readPref("secondaryPreferred")
// 6. Avoid Unbounded Arrays
db.users.updateOne(
{ username: "johndoe" },
{ $push: {
recentPosts: {
$each: [{ title: "New post", content: "Check this out!", likes: 0 }],
$slice: -10 // Keep only the 10 most recent posts
}
}
}
)
// 7. Use Aggregation for Complex Queries
db.users.aggregate([
{ $match: { "profile.location": "New York" } },
{ $unwind: "$recentPosts" },
{ $group: {
_id: "$username",
totalLikes: { $sum: "$recentPosts.likes" },
avgLikes: { $avg: "$recentPosts.likes" }
}
},
{ $sort: { totalLikes: -1 } },
{ $limit: 10 }
])
These examples demonstrate schema design, indexing, TTL indexes, write concerns, read preferences, managing array growth, and using aggregation for complex queries.
🎨 Novice Explanation: Following MongoDB best practices is like being a master chef in a busy kitchen 👨🍳:
- Your recipe (schema design) needs to be well-planned and flexible.
- You keep your most-used ingredients (indexes) close at hand for quick access.
- You clean up old food (TTL indexes) to keep your fridge (database) fresh.
- You have different cooking techniques (write concerns, read preferences) for different dishes.
- And you always keep an eye on your pots and pans (monitoring) to make sure nothing’s burning!
By following these practices, you ensure your MongoDB “kitchen” runs smoothly, can handle lots of “customers” (users), and produces delicious “meals” (data) efficiently! 🍽️